I’ve been using SSMS 21 for the last fortnight and below are my first impressions, I’ve used SSMS in its many forms since around 2006 not long after it was first released.
The new connection dialog
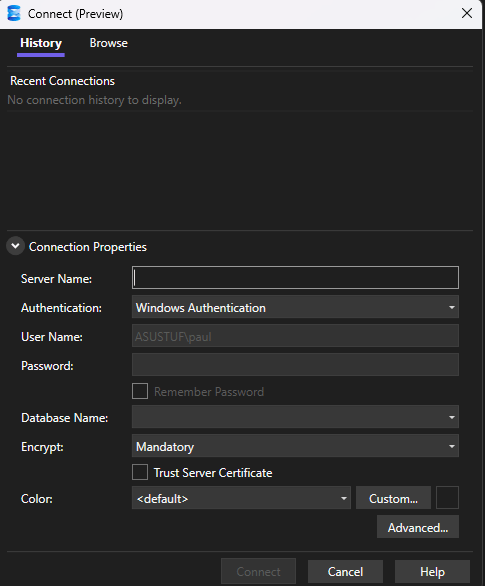
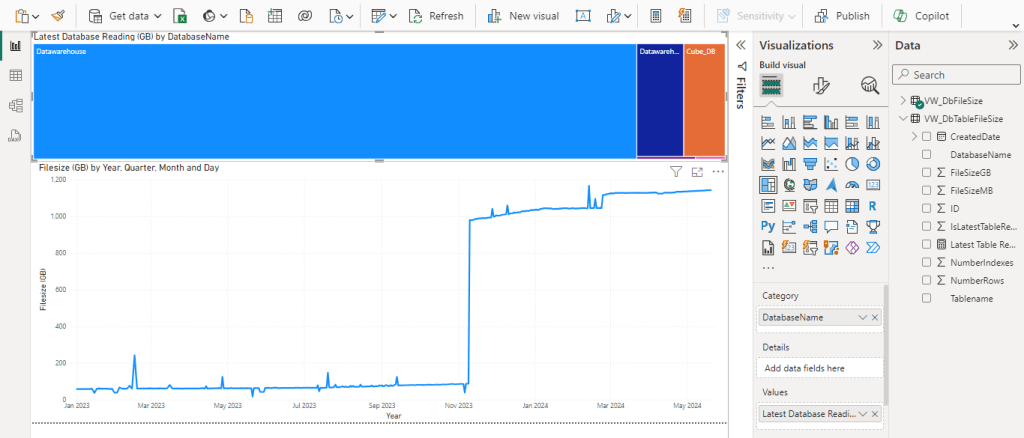
The new connection dialog is very similar to the connection dialog box in Azure Data Studio (which has also been announced as being retired in February 2026), it makes switching between commonly used servers straight forward, allows you to set the default database to use when connecting and the service (SSAS, SSRS, database engine etc). This saves time and is a simple welcome change.
Dark Mode
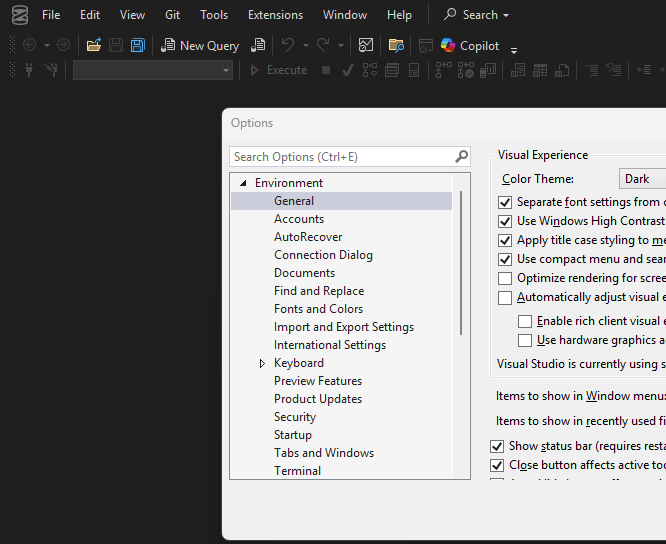
Met with applause when it was announced at SQL Bits, dark mode is something that most data professionals have been keen on for SSMS. However not all dialogs/menus have been configured to operate in dark mode yet (see the example above), when I spoke to Erin from Microsoft she said that they were viewing the functionality of dark mode in each menu/screen as an ongoing task. As opposed to waiting for everything to be done prior to rolling it out to users.
Whilst I use dark mode across Outlook, teams and Visual Studio, I am still a bit undecided on dark mode in SSMS. It is much easier on the eyes though, especially when you use a screen all day!
Copilot
I haven’t made use of the copilot features yet, so a big omission in my testing here. As it requires a licence and also I have some questions on what data it sends (query text or query results) before I can look at using it.
Issues
Existing SQL agent jobs that have steps that execute an SSIS package appear blank when opening them, I attempted to report this to Microsoft however they don’t consider this a bug due to SSIS not coming under the permit of SSMS 21 yet. This is really disappointing and users need to be careful they still have SSMS 20 to manage jobs of this type.
I’ve had a few instances of it freezing, this has been difficult to repeat and have received updates to SSMS 21 since then, so might have already been addressed.
The new icon for SSMS is perfectly fine, but muscle memory leaves me pausing, looking for the old trusty golden cylinder and crossed tools, however that is very much a me problem!